LSM基本概念与其经典实现Level-DB
前言
LSM 是以牺牲读取性能以及空间利用率为代价而换取顺序写入性能的。因此,对LSM结构的优化目标就是想办法提高读取性能和空间利用率。读取性能的瓶颈在于读写放大以及合并压缩过程的抖动。
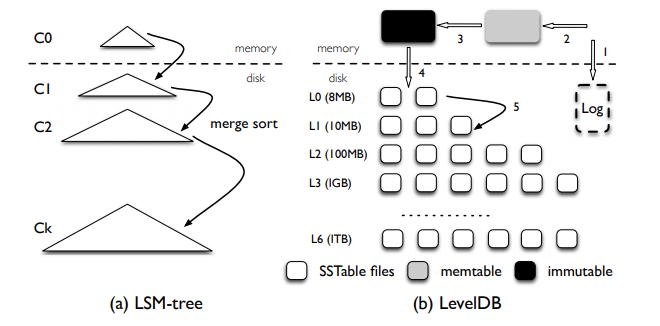
LSM经典实现Level-DB:Level引入分层机制
1、将最近最新写入的kv存储在内存数据结构中,如红黑树,跳表等。 那么问题是何时将此数据结构dump到磁盘?最简单的是根据其大小的区别,然而在dump之前我们不能继续向其中写入数据,因此在内存中应该存在一个活跃内存表和一个不变内存表,二者相互交替,周期性的将不变内存表dump到内存中形成一个分段文件。
2、为了优化LSM的读取性能:
LSM结构引入了分层设计的思想。将所有的kv文件分为c0-ck 共k+1层。c0层是直接从不变的内存表中dump下的结果。而c1-ck是发生过合并的文件。由于ci+1 是ci中具有重叠部分的文件合并的产物,因此可以说在同一层内是不存在重叠key的,因为重叠key已经在其上一层被合并了。那么只有c0层是可能存在重叠的文件的。所以当要读取磁盘上的数据时,最坏情况下只需要读取c0的所有文件以及c1-ck每一层中的一个文件即c0+k个文件即可找到key的位置,分层合并思想使得非就地更新索引在常数次的IO中读取数据。
通常c0文件定义为2M,每一级比上一级大一个数量级的文件大小。所以高层的文件难以被一次性的加载到内存,因此需要一定的磁盘索引机制。我们对每个磁盘文件进行布局设计,分为元数据块,索引块,数据块三大块。元数据块中存储布隆过滤器快速的判断这个文件中是否存在某个key,同时通过对排序索引(通常缓存在内存中)二分查找定位key所在磁盘的位置。进而加速读取的速度,我们叫这种数据文件为SSTABLE(字符串排序表)。
为了标记哪些SStable属于那一层因此要存在一个sstable的元数据管理文件,在levelDB中叫做MANIFEST文件。其中存储每一个sstable的文件名,所属的级别,最大与最小key的前缀。
解读
- 内存中的数据周期性的dump到磁盘中,一次dump就是在磁盘中写入一个sstable文件。
- 每一次从内存中dump到磁盘中的文件自动成为第零层L0中的文件。LSM每一层都可以有多个文件。第零层也不例外,会存在多个从内存中dump下来的文件,因此每个文件中的KV数据都是排好序的,并且每个文件元数据中都包含这个文件的最大key和最小key。比如file1[k1 -> k100],file2[k50 -> k150],这两个文件就存在重叠的key,需要进行压缩归并,从而保证同一层内所有文件不能存在重叠key。
- 通过对比每个从内存中dump下来的文件的key区间,我们很容易的判断出两个文件中是否含有重叠的key区间,如果有,那么就要触发压缩,也就是归并排序,将这两个文件进行压缩合并。合并后会生成一个新的文件,同时L0层的两个文件就可以删掉了,由于这个文件是L0层的文件压缩合并而来的,因此这个文件会晋升到L1层,依次递归。
LSM Compaction机制
compaction在以LSM-Tree为架构的系统中是非常关键的模块,log append的方式带来了高吞吐的写,内存中的数据到达上限后不断刷盘,数据范围互相交叠的层越来越多,相同key的数据不断积累,引起读性能下降和空间膨胀。因此,compaction机制被引入,通过周期性的后台任务不断的回收旧版本数据和将多层合并方式来优化读性能和空间问题。而compaction的策略和任务调度成为新的难题,看似简单的功能,实则需要各方面的权衡,涉及空间、I/O、cpu资源和缓存等多个层面。这篇文章将从compaction策略、挑战、几个主流lsmtree系统的实现和学术上的研究几个方向来探讨这个机制。
compaction策略
compaction的主要作用是数据的gc和归并排序,是lsm-tree系统正常运转必须要做的操作,但是compaction任务运行期间会带来很大的资源开销,压缩/解压缩、数据拷贝和compare消耗大量cpu,读写数据引起disk I/O。compaction策略约束了lsm-tree的形状,决定哪些文件需要合并、任务的大小和触发的条件,不同的策略对读写放大、空间放大和临时空间的大小有不同的影响,一般系统会支持不同的策略并配有多个调整参数,可根据不同的应用场景选取更合适的方式。
Size-tired compaction
- size-tired适合write-intensive workload,有较低的写放大,缺点是读放大和空间放大较高。

leveled compaction
- leveled策略可以减小空间放大和读放大。leveled策略的问题是写放大。

Hybrid
- tiered和leveled混合的方式。很多系统使用两者混合的方式以取得读写放大、空间放大之间进一步的权衡。相比tiered可以获得更少的空间放大和读放大,相比leveled可以有更少的写放大。
Compaction in RocksDB
由于Size-tired compaction和leveled compaction两种策略都有各自的优缺点,所以RocksDB在L1层及以上采用leveled compaction,而在L0层采用size-tiered compaction。

universal compaction
universal compaction是RocksDB中size-tiered compaction的别名,专门用于L0层的compaction,因为L0层的SST的key区间是几乎肯定有重合的。
前文已经说过,当L0层的文件数目达到level0_file_num_compaction_trigger阈值时,就会触发L0层SST合并到L1。universal compaction还会检查以下条件。
空间放大比例
假设L0层现有的SST文件为(R1, R1, R2, …, Rn),其中R1是最新写入的SST,Rn是较旧的SST。所谓空间放大比例,就是指R1~Rn-1文件的总大小除以Rn的大小,如果这个比值比max_size_amplification_percent / 100要大,那么就会将L0层所有SST做compaction。相邻文件大小比例
有一个参数size_ratio用于控制相邻文件大小比例的阈值。如果size(R2) / size(R1)的比值小于1 + size_ratio / 100,就表示R1和R2两个SST可以做compaction。接下来继续检查size(R3) / size(R1 + R2)是否小于1 + size_ratio / 100,若仍满足,就将R3也加入待compaction的SST里来。如此往复,直到不再满足上述比例条件为止。
当然,如果上述两个条件都没能触发compaction,该策略就会线性地从R1开始合并,直到L0层的文件数目小于level0_file_num_compaction_trigger阈值。
LSM in paimon
写入
paimon并没有在内存中维护一个排序数据结构,比如红黑树或者跳表,而是直接追加写入到内存中,当到达一定大小,需要dump到磁盘时,才会进行排序,并flush到文件系统。
paimon为什么不在内存中维护一个排序数据结构,是因为相比其他LSM系统如HBase、Kudu、Doris等,不是一个在线的服务,更像一种表格式。不支持从内存中查找最新的数据,只有当内存中的数据dump到文件系统以后,才会保证数据的可见性,更准确的说是完成快照以后,数据才可见。因此paimon相比其他数据系统拥有更大的数据延迟,因为其不支持从内存中查找最新的数据。
paimon会将到来的Record对象先序列化为二进制字节,以节省内存空间,再将序列化后的Record写入到LSM的内存缓存区中。一切的一切都是为了减少内存空间占用。
压缩策略Compact Strategy
paimon采用类似于Rocksdb的universal compaction的压缩策略。
 嘻嘻!!!
嘻嘻!!!
