理解Spark ESS
spark shuffle大概过程
spark shuffle分为两部分shuffle write和shuffle read。
在map write端,对每个task的数据,不管是按key hash还是在数据结构里先聚合再排序,最终都会将数据写到一个partitionFile里面,在partitionFile里面的数据是partitionId有序的,外加会生成一个索引文件,索引包含每个partition对应偏移量和长度。
而reduce read 端就是从这些partitionFile里面拉取相应partitionId的数据, 然后再进行聚合排序。
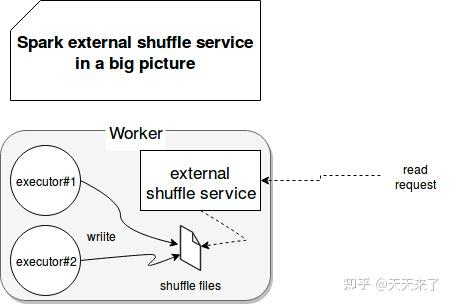
现在我们在来看下external shuffle service(ESS),其乍从其名字上看,ESS是spark分布式集群为存储shuffle data而设计的分布式组件。但其实它只是Spark通过Executor获取Shuffle data块的代理。
我们可以理解为ESS负责管理shuffle write端生成的shuffle数据,ESS是和yarn一起使用的, 在yarn集群上的每一个nodemanager上面都运行一个ESS,是一个常驻进程。一个ESS管理每个nodemanager上所有的executor生成的shuffle数据。总而言之,ESS并不是分布式的组件,它的生命周期也不依赖于Executor。
为什么需要ESS ?
在Spark中,Executor进程除了运行task,还要负责写shuffle 数据,以及给其他Executor提供shuffle数据。当Executor进程任务过重,导致GC而不能为其他Executor提供shuffle数据时,会影响任务运行。同时,ESS的存在也使得,即使executor挂掉或者回收,都不影响其shuffle数据,因此只有在ESS开启情况下才能开启动态调整executor数目。
因此,spark提供了external shuffle service这个接口,常见的就是spark on yarn中的,YarnShuffleService。这样,在yarn的nodemanager中会常驻一个externalShuffleService服务进程来为所有的executor服务,默认为7337端口。
其实在spark中shuffleClient有两种,一种是blockTransferService,另一种是externalShuffleClient。如果在ESS开启,那么externalShuffleClient用来fetch shuffle数据,而blockTransferService用于获取broadCast等其他BlockManager保存的数据。
如果ESS没有开启,那么spark就只能使用自己的blockTransferService来拉取所有数据,包括shuffle数据以及broadcast数据。
ESS的架构与优势
在启用ESS后,ESS服务会在node节点上创建,并且每次存在时,新创建的Executor都会向其注册。
在注册过程中,使用appId, execId和ExecutorShuffleInfo(localDirs, shuffleManager类型)作为参数,从参数信息可以看出Executor会通知ESS服务它创建在磁盘上文件的存储位置。由于这些信息,ESS服务守护进程能够在检索过程中将shuffle中间的临时文件返回给其他执行程序。
ESS服务的存在也会影响文件删除。在正常情况下(没有外部 shuffle 服务),当Executor停止时,它会自动删除生成的文件。但是启用ESS服务后,Executor关闭后文件不会被清理。以下架构图说明了启用外部 shuffle 服务时工作程序节点上发生的情况:
ESS服务的一大优势是提高了可靠性。即使其中一个 executor 出现故障,它的 shuffle 文件也不会丢失。另一个优点是可扩展性,因为在 Spark 中运行动态资源分配需要ESS服务,这块我们后续在进行介绍。
总之使用Spark ESS 为 Spark Shuffle 操作带来了以下好处:
- 即使 Spark Executor 正在经历 GC 停顿,Spark ESS 也可以为 Shuffle 块提供服务。
- 即使产生它们的 Spark Executor 挂了,Shuffle 块也能提供服务。
- 可以释放闲置的 Spark Executor 来节省集群的计算资源。
Spark 3.2新特性Push-based Shuffle
Spark 3.2为spark shuffle带来了重大的改变,其中新增了push-based shuffle机制。但其实在push-based shuffle 之前,业界也有人提出了remote shuffle service的实践,不过由于它们是依赖于外部组件实现的所以一直不被社区所接收。
在上一讲我们先来了解push-based shuffle机制的实现原理,这里我们来通过源码分析下其实现的过程。
首先,Push-based shuffle机制是不依赖于外部组件的方案,但使用升级版的ESS进行shuffle data的合并,所以PBS(Push-based shuffle)只支持Yarn方式的实现。
其次,引入PBS新特性的主要原因是为了解决大shuffle的场景存在的问题:
- 第一个挑战是可靠性问题。由于计算节点数据量大和 shuffle 工作负载的规模,可能会导致 shuffle fetch 失败,从而导致昂贵的 stage 重试。
- 第二个挑战是效率问题。由于 reducer 的 shuffle fetch 请求是随机到达的,因此 shuffle 服务也会随机访问 shuffle 文件中的数据。如果单个 shuffle 块大小较小,则 shuffle 服务产生的小随机读取会严重影响磁盘吞吐量,从而延长 shuffle fetch 等待时间。
- 第三个挑战是扩展问题。由于 external shuffle service 是我们基础架构中的共享服务,因此一些对 shuffle services 错误调优的作业也会影响其他作业。当一个作业错误地配置导致产生许多小的 shuffle blocks 将会给 shuffle 服务带来压力时,它不仅会给自身带来性能下降,还会使共享相同 shuffle 服务的所有相邻作业的性能下降。这可能会导致原本正常运行的作业出现不可预测的运行时延迟,尤其是在集群高峰时段。
此外,PBS不仅适用于大shuffle的场景,对于大量小shuffle文件,这种严重影响磁盘IO性能的情况下, 也有很好的性能提升。push-based shuffle并不是来替换sort-based shuffle, 它是通过补充的方式来优化shuffle。
Push-based Shuffle主要分为以下:shuffle service 准备、Map端push shuffle数据、shuffle service merge数据、更新MergeStatues和reducer拉取merge shuffle 数据五部分。
多版本ESS和push-based shuffle
yarn-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle,spark_shuffle,spark3_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.spark_shuffle.class</name>
<value>org.apache.spark.network.yarn.YarnShuffleService</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.spark3_shuffle.class</name>
<value>org.apache.spark.network.yarn.YarnShuffleService</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.spark_shuffle.classpath</name>
<value>/opt/spark/yarn/*:/opt/hadoop/etc/hadoop/ess/spark-2-config</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.spark3_shuffle.classpath</name>
<value>/opt/spark3/yarn/*:/opt/hadoop/etc/hadoop/ess/spark-3-config</value>
</property>
<property>
<name>spark.shuffle.push.server.mergedShuffleFileManagerImpl</name>
<value>org.apache.spark.network.shuffle.RemoteBlockPushResolver</value>
</property>spark-defaults.conf
1
2
3
4
5
6# Spark ESS: with push-based shuffle service
# spark.shuffle.useOldFetchProtocol=true
spark.shuffle.service.name=spark3_shuffle
spark.shuffle.service.port=7773
spark.shuffle.push.enabled=true
spark.shuffle.push.mergersMinStaticThreshold=5
 嘻嘻!!!
嘻嘻!!!


