一文搞懂Kudu的整体架构
Kudu是典型的Master-Slave架构,基于LSM优化写入性能,但同时读性能会低(相较于Parquet)。Kudu基于Raft协议实现了Master和Slave Tablet节点的数据的一致性,以及选举功能,保证了容错性和高可用。
Kudu是完全的列式存储引擎,可以针对性的编码和压缩,提高了IO性能。HBase是基于列族的,No Schema的NoSQL、KV数据库,无法进行针对性的编码和压缩,同时一般情况只会用一个列族,其实HBase退化为行存储引擎。
Kudu通过WAL和Raft保证了分布式数据的一致性。
kudu相对于HBase,牺牲了一定的写入性能—>Kudu在写入数据的时候,需要先检查一遍唯一主键是否存在,如果存在会报错,同样更新数据的时候,同样需要先查找主键是否存在。因此Insert和Update等所有操作比HBase多了,
先读一次的开销,而HBase所有的操作都是转化为直接写入,因此写的性能相较于HBase有一定的劣势。Kudu牺牲写的性能,但是保证了一个主键,只会存在于一个RowSet中,而HBase的RowKey可能会在多个HFlie中。减少了IO,提升了读性能,特别是在大量写入,少量更新的情况下。
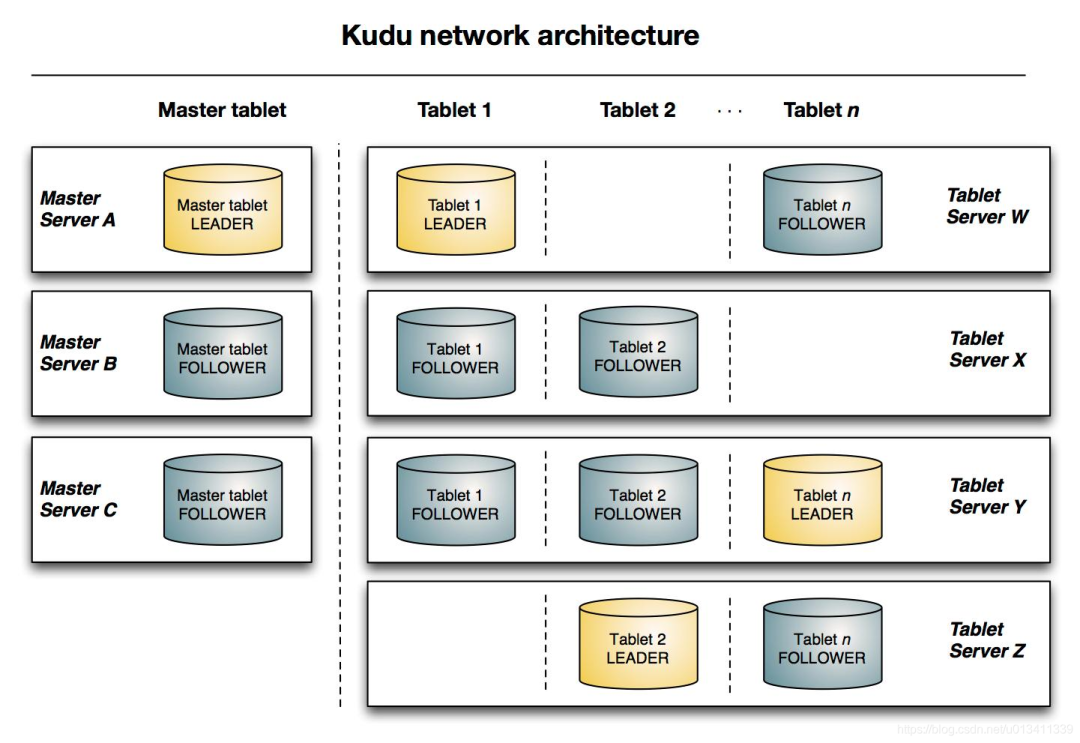
Table:具有Schema和全局有序主键的表。一张表有多个Tablet,多个Tablet包含表的全部数据。
Tablet:Kudu的表Table被水平分割为多段,Tablet是Kudu表的一个片段(分区),每个Tablet存储一段连续范围的数据(会记录开始Key和结束Key),且两个Tablet间不会有重复范围的数据。一个Tablet会复制(逻辑复制而非物理复制,副本中的内容不是实际的数据,而是操作该副本上的数据时对应的更改信息)多个副本在多台TServer上,其中一个副本为Leader Tablet,其他则为Follower Tablet。只有Leader Tablet响应写请求,任何Tablet副本可以响应读请求。
TabletServer:简称TServer,负责数据存储Tablet、提供数据读写服务、编码、压缩、合并和复制。一个TServer可以是某些Tablet的Leader,也可以是某些Tablet的Follower,一个Tablet可以被多个TServer服务(多对多关系)。TServer会定期(默认1s)向Master发送心跳。
Catalog Table:目录表,用户不可直接读取或写入,仅由Master维护,存储两类元数据:表元数据(Schema信息,位置和状态)和Tablet元数据(所有TServer的列表、每个TServer包含哪些Tablet副本、Tablet的开始Key和结束Key)。Catalog Table只存储在Master节点,也是以Tablet的形式,数据量不会很大,只有一个分区,随着Master启动而被全量加载到内存。
Master:负责集群管理和元数据管理。具体:跟踪所有Tablets、TServer、Catalog Table和其他相关的元数据。协调客户端做元数据操作,比如创建一个新表,客户端向Master发起请求,Master写入其WAL并得到其他Master同意后将新表的元数据写入Catalog Table,并协调TServer创建Tablet。
WAL:一个仅支持追加写的预写日志,无论Master还是Tablet都有预写日志,任何对表的修改都会在该表对应的WAL中写入条目(entry),其他副本在数据相对落后时可以通过WAL赶上来。
逻辑复制:Kudu基于Raft协议在集群中对每个Tablet都存储多个副本,副本中的内容不是实际的数据,而是操作该副本上的数据时对应的更改信息。Insert和Update操作会走网络IO,但Delete操作不会,压缩数据也不会走网络。
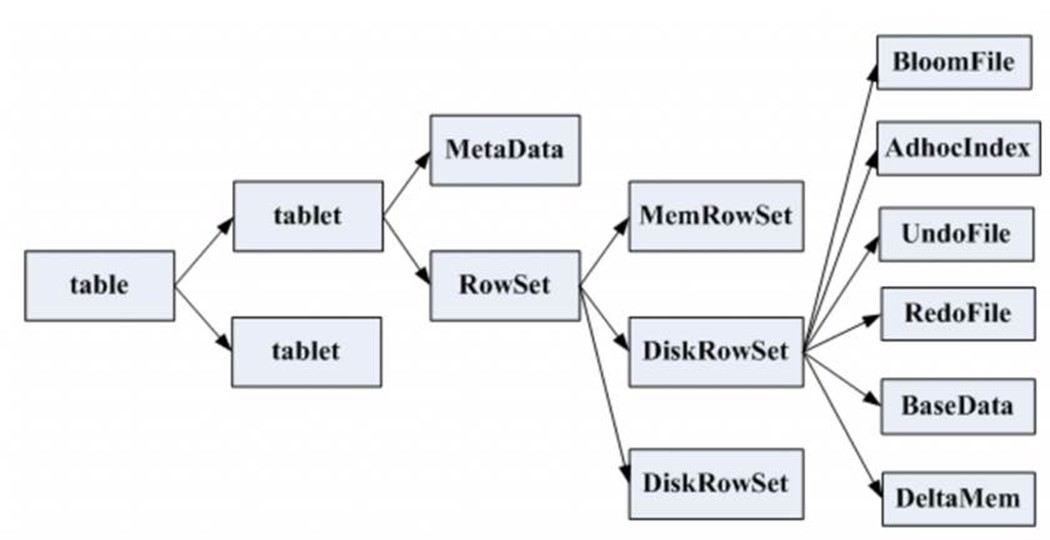
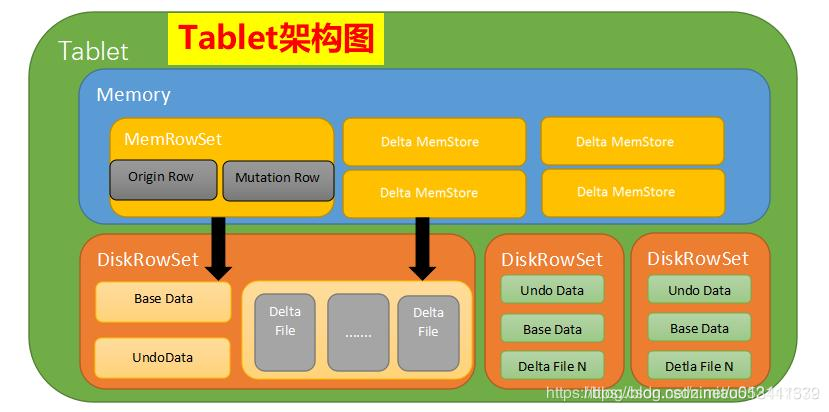
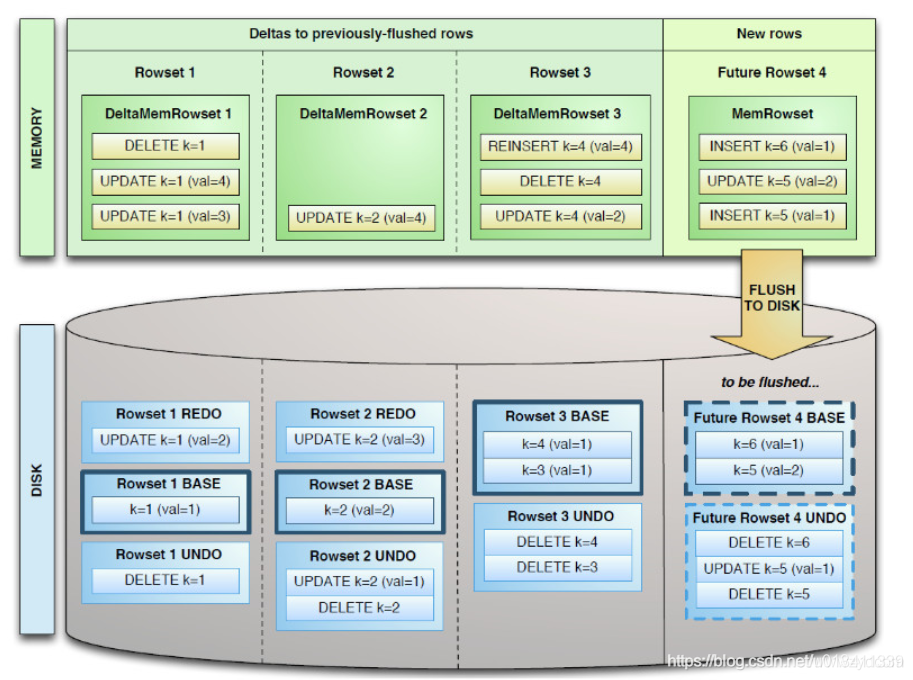
如图,Table分为若干Tablet;Tablet包含Metadata和RowSet,RowSet包含一个MemRowSet及若干个DiskRowSet,DiskRowSet中包含一个BloomFile、AdhocIndex、BaseData、DeltaMem及若干个RedoFile和UndoFile(UndoFile一般情况下只有一个)。
MemRowSet:插入新数据及更新已在MemRowSet中的数据,数据结构是B+树,主键在非叶子节点,数据都在叶子节点。MemRowSet写满后会将数据刷到磁盘形成若干个DiskRowSet。每次达到1G或者120s时生成一个DiskRowSet,DiskRowSet按列存储,类似Parquet。
DiskRowSet:DiskRowSets存储文件格式为CFile。DiskRowSet分为BaseData和DeltaFile。这里每个Column被存储在一个相邻的数据区域,这个数据区域被分为多个小的Page,每个Column Page都可以使用一些Encoding以及Compression算法。后台会定期对DiskRowSet做Compaction,以删除没用的数据及合并历史数据,减少查询过程中的IO开销。
BaseData:DiskRowSet刷写完成的数据,CFile,按列存储,主键有序。BaseData不可变,类似Parquet。
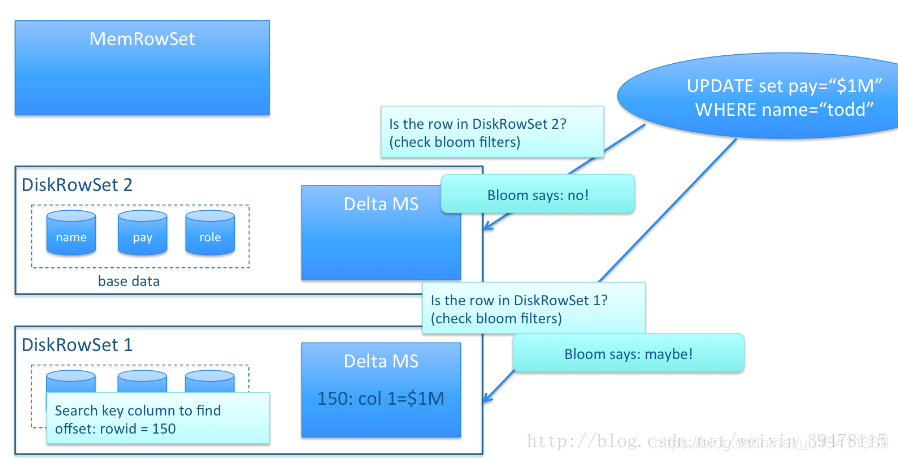
BloomFile:根据一个DiskRowSet中的Key生成一个BloomFilter,用于快速模糊定位某个key是否在DiskRowSet中存在。
AdhocIndex:存放主键的索引,用于定位Key在DiskRowSet中的具体哪个偏移位置。
DeltaMemStore:每份DiskRowSet都对应内存中一个DeltaMemStore,负责记录这个DiskRowSet上BaseData发生后续变更的数据,先写到内存中,写满后Flush到磁盘生成RedoFile。DeltaMemStore的组织方式与MemRowSet相同,也维护一个B+树。
DeltaFile:DeltaMemStore到一定大小会存储到磁盘形成DeltaFile,分为UndoFile和RedoFile。
RedoFile:重做文件,记录上一次Flush生成BaseData之后发生变更数据。DeltaMemStore写满之后,也会刷成CFile,不过与BaseData分开存储,名为RedoFile。UndoFile和RedoFile与关系型数据库中的Undo日子和Redo日志类似。
UndoFile:撤销文件,记录上一次Flush生成BaseData之前时间的历史数据,Kudu通过UndoFile可以读到历史某个时间点的数据。UndoFile一般只有一份。默认UndoFile保存15分钟,Kudu可以查询到15分钟内某列的内容,超过15分钟后会过期,该UndoFile被删除。
DeltaFile(主要是RedoFile)会不断增加,产生大量小文件,不Compaction肯定影响性能,所以就有了下面两种合并方式:
- Minor Compaction:多个DeltaFile进行合并生成一个大的DeltaFile。默认是1000个DeltaFile进行合并一次。
- Major Compaction:RedoFile文件的大小和BaseData的文件的比例为0.1的时候,会将RedoFile合并进入BaseData,Kudu记录所有更新操作并保存为UndoFile。
补充一下:合并和重写BaseData是成本很高的,会产生大量IO操作,Kudu不会将全部DeltaFile合并进BaseData。如果只更新几行数据,但要重写BaseData,费力不讨好,所以Kudu会在某个特定列需要大量更新时再把BaseData与DeltaFile合并。未合并的RedoFile会继续保留等待后续合并操作。
Kudu读流程: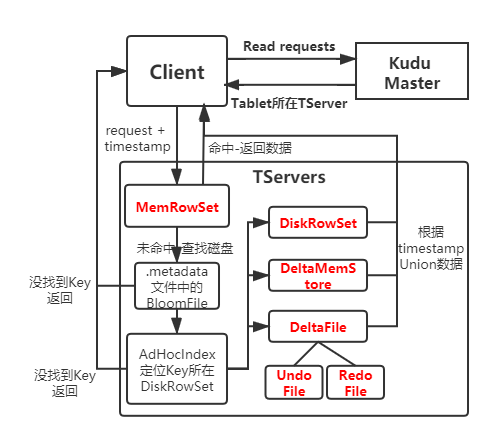
- Client发送读请求,Master根据主键范围确定到包含所需数据的所有Tablet位置和信息。
- Client找到所需Tablet所在TServer,TServer接受读请求。
- 如果要读取的数据位于内存,先从内存(MemRowSet,DeltaMemStore)读取数据,根据读取请求包含的时间戳前提交的更新合并成最终数据。
- 如果要读取的数据位于磁盘(DiskRowSet,DeltaFile),在DeltaFile的UndoFile、RedoFile中找目标数据相关的改动,根据读取请求包含的时间戳合并成最新数据并返回。
Kudu写流程: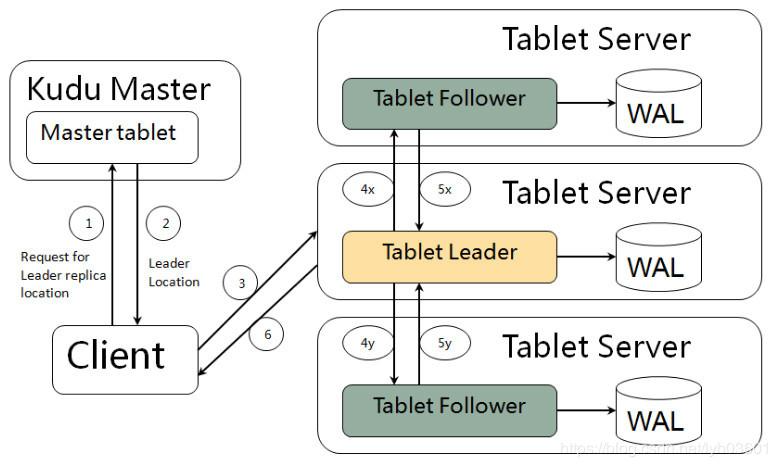
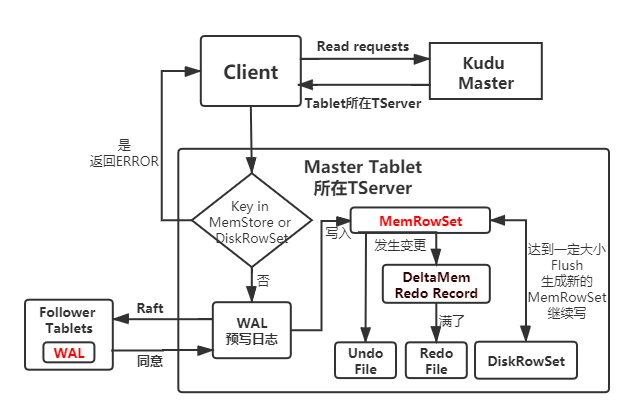
- Client向Master发起写请求,Master找到对应的Tablet元数据信息,检查请求数据是否符合表结构。
- 因为Kudu不允许有主键重复的记录,所以需要判断主键是否已经存在,先查询主键范围,如果不在范围内则准备写MemRowSet。
- 如果在主键范围内,先通过主键Key的布隆过滤器快速模糊查找,未命中则准备写MemRowSet。
- 如果BloomFilter命中,则查询索引,如果没命中索引则准备写MemRowSet,如果命中了主键索引就报错:主键重复。
- 写入MemRowSet前先被提交到一个Tablet的WAL预写日志,并根据Raft一致性算法取得Follower Tablets的同意,然后才会被写入到其中一个Tablet的MemRowSet中。为了在MemRowSet中支持多版本并发控制(MVCC),对最近插入的行(即尚未刷新到磁盘的新的行)的更新和删除操作将被追加到MemRowSet中的原始行之后以生成重做(REDO)记录的列表。
- MemRowSet写满后,Kudu将数据每行相邻的列分为不同的区间,每个列为一个区间,Flush到DiskRowSet。
Kudu更新流程:
- Client发送更新请求,Master获取表的相关信息,表的所有Tablet信息。
- Kudu检查是否符合表结构。
- 如果需要更新的数据在MemRowSet,B+树找到待更新数据所在叶子节点,然后将更新操作记录在所在行中一个Mutation链表中;Kudu采用了MVCC(多版本并发控制,实现读和写的并行,任何写都是插入)思想,将更改的数据以链表形式追加到叶子节点后面,避免在树上进行更新和删除操作。
- 如果需要更新的数据在DiskRowSet,找到其所在的DiskRowSet,前面提到每个DiskRowSet都会在内存中有一个DeltaMemStore,将更新操作记录在DeltaMemStore,达到一定大小才会生成DeltaFile到磁盘。
 嘻嘻!!!
嘻嘻!!!
